Node classification is a fundamental task in graph analysis, with broad applications across various fields. Recent breakthroughs in Large Language Models (LLMs) have enabled LLM-based approaches for this task. Although many studies demonstrate the impressive performance of LLM-based methods, the lack of clear design guidelines may hinder their practical application. In this work, we aim to establish such guidelines through a fair and systematic comparison of these algorithms. As a first step, we developed LLMNodeBed, a comprehensive codebase and testbed for node classification using LLMs. It includes 10 homophilic datasets, 4 heterophilic datasets, 8 LLM-based algorithms, 8 classic baselines, and 3 learning paradigms. Subsequently, we conducted extensive experiments, training and evaluating over 2,700 models, to determine the key settings (e.g., learning paradigms and homophily) and components (e.g., model size and prompt) that affect performance. Our findings uncover 8 insights, e.g., (1) LLM-based methods can significantly outperform traditional methods in a semi-supervised setting, while the advantage is marginal in a supervised setting; (2) Graph Foundation Models can beat open-source LLMs but still fall short of strong LLMs like GPT-4o in a zero-shot setting. We hope that the release of LLMNodeBed, along with our insights, will facilitate reproducible research and inspire future studies in this field.
📊 A Testbed We release LLMNodeBed, a PyG-based testbed designed to facilitate reproducible and rigorous research in LLM-based node classification algorithms. The initial release includes 14 datasets, 8 LLM-based algorithms, 8 classic baselines, and 3 learning configurations. LLMNodeBed allows for easy addition of new algorithms or datasets, and a single command to run all experiments, and to automatically generate all tables included in this work.
🔍 Comprehensive Experiments By training and evaluating over 2,700 models, we analyzed how the learning paradigm, homophily, language model type and size, and prompt design impact the performance of each algorithm category.
📚 Insights and Tips Detailed experiments were conducted to analyze each influencing factor. We identified the settings where each algorithm category performs best and the key components for achieving this performance. Our work provides intuitive explanations, practical tips, and insights about the strengths and limitations of each algorithm category.
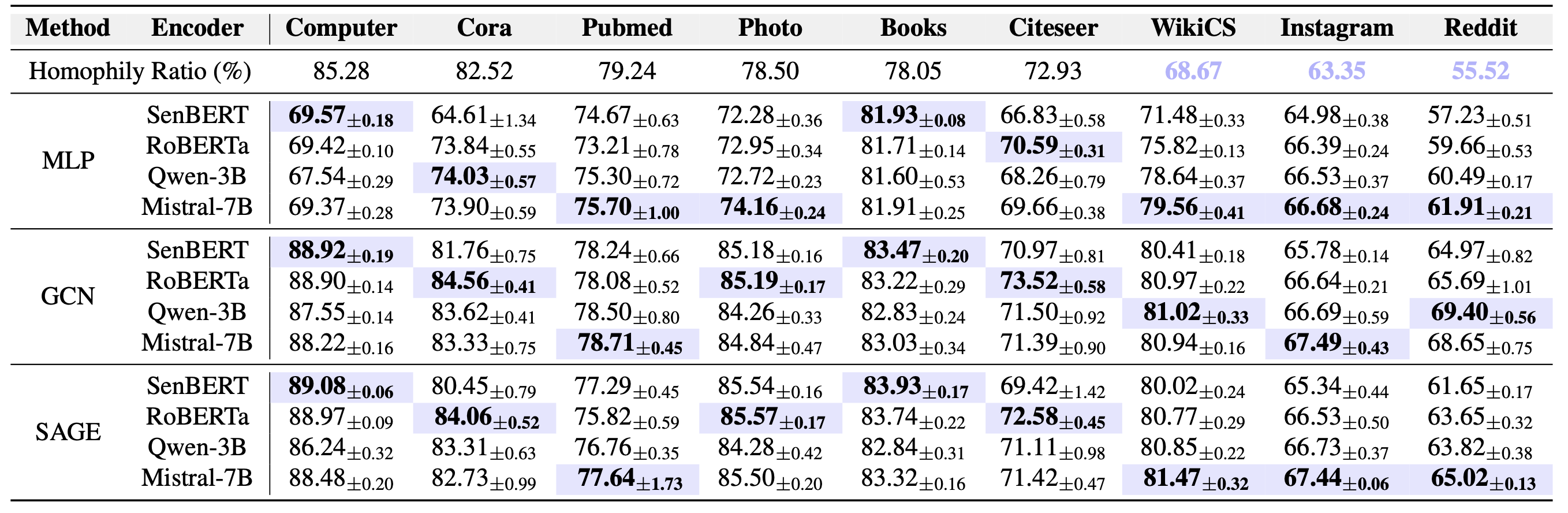
Datasets LLMNodeBed comprises 14 datasets spanning the academic, web link, social, and E-Commerce domains. These datasets vary significantly in scale, ranging from thousands of nodes to millions of edges, and exhibit differing levels of homophily.
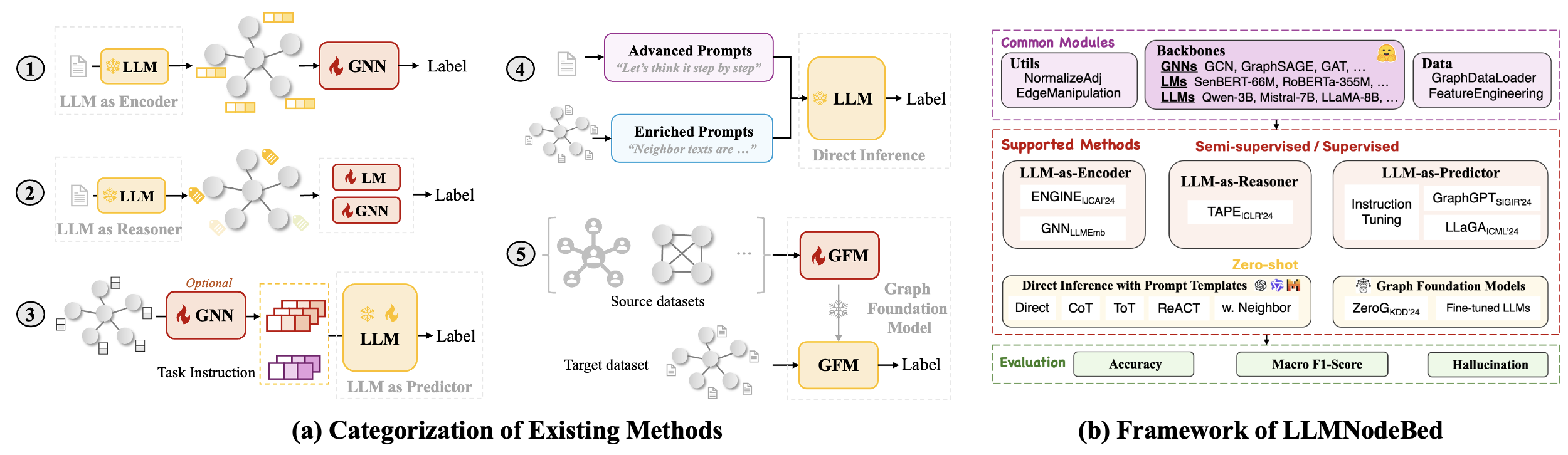
Baselines LLMNodeBed includes 8 LLM-based baseline algorithms alongside 8 classic methods. (1) LLM-as-Encoder: ENGINE and GNN w. LLMEmb, (2) LLM-as-Explainer: TAPE, (3) LLM-as-Predictor: LLM Instruction Tuning, GraphGPT, and LLaGA, (4) LLM Direct Inference with both Advanced Prompts and Enriched Prompts, (5) Graph Foundation Models: ZeroG
Learning Paradigms Baselines are evaluated under three learning configurations: Semi-supervised, Supervised, and Zero-shot.
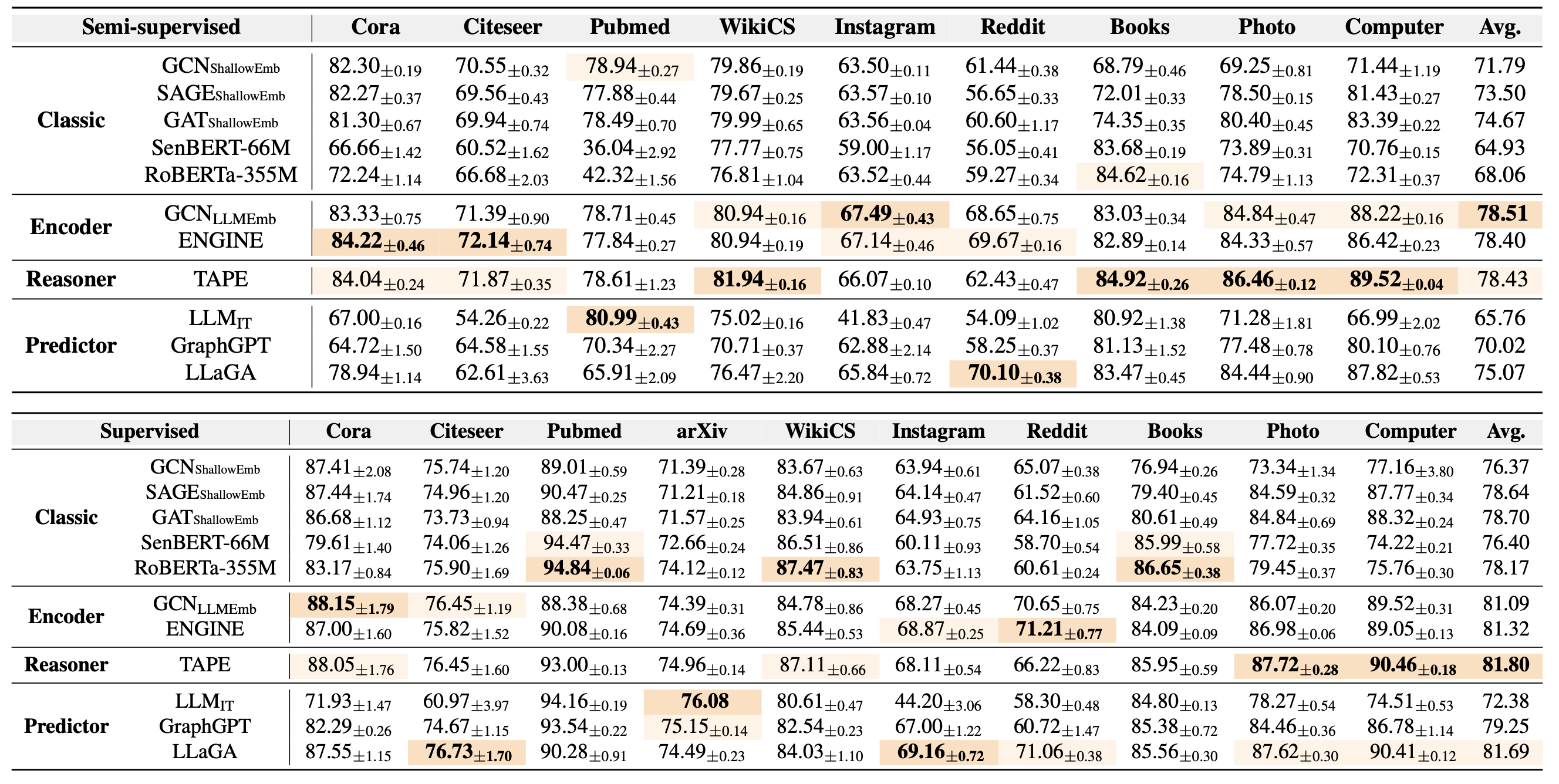
The performance comparison under semi-supervised and supervised settings measured by Accuracy (%), is reported above.
📚 Our key takeaways are as follows:
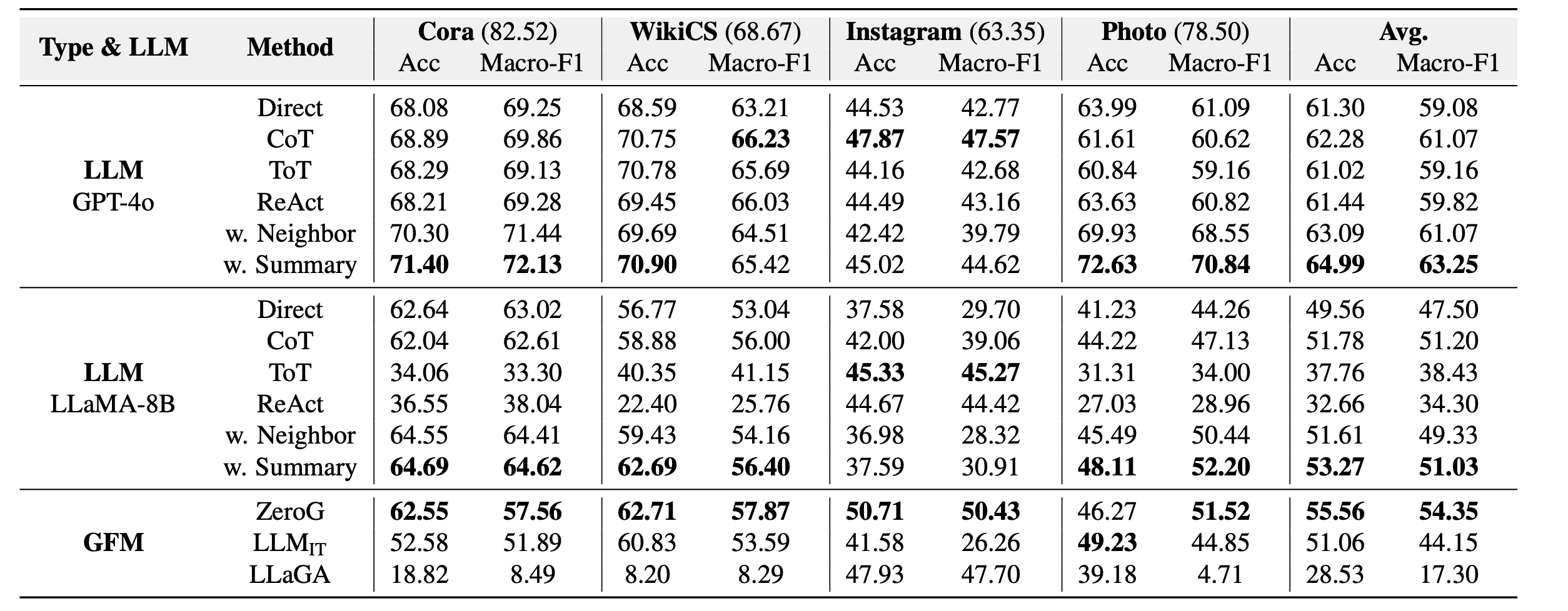
The performance comparison under zero-shot settings measured by Accuracy (%) and Macro-F1 (%), is reported above.
📚 Our key takeaways are as follows:
Feel free to cite this work if you find it useful to you!
@inproceedings{wu2025llmnodebed,
title={When Do LLMs Help With Node Classification? A Comprehensive Analysis},
author={Xixi Wu and Yifei Shen and Fangzhou Ge and Caihua Shan and Yizhu Jiao and Xiangguo Sun and Hong Cheng},
year={2025},
booktitle={International Conference on Machine Learning},
organization={PMLR},
url={https://arxiv.org/abs/2502.00829},
}